$ llama-manager
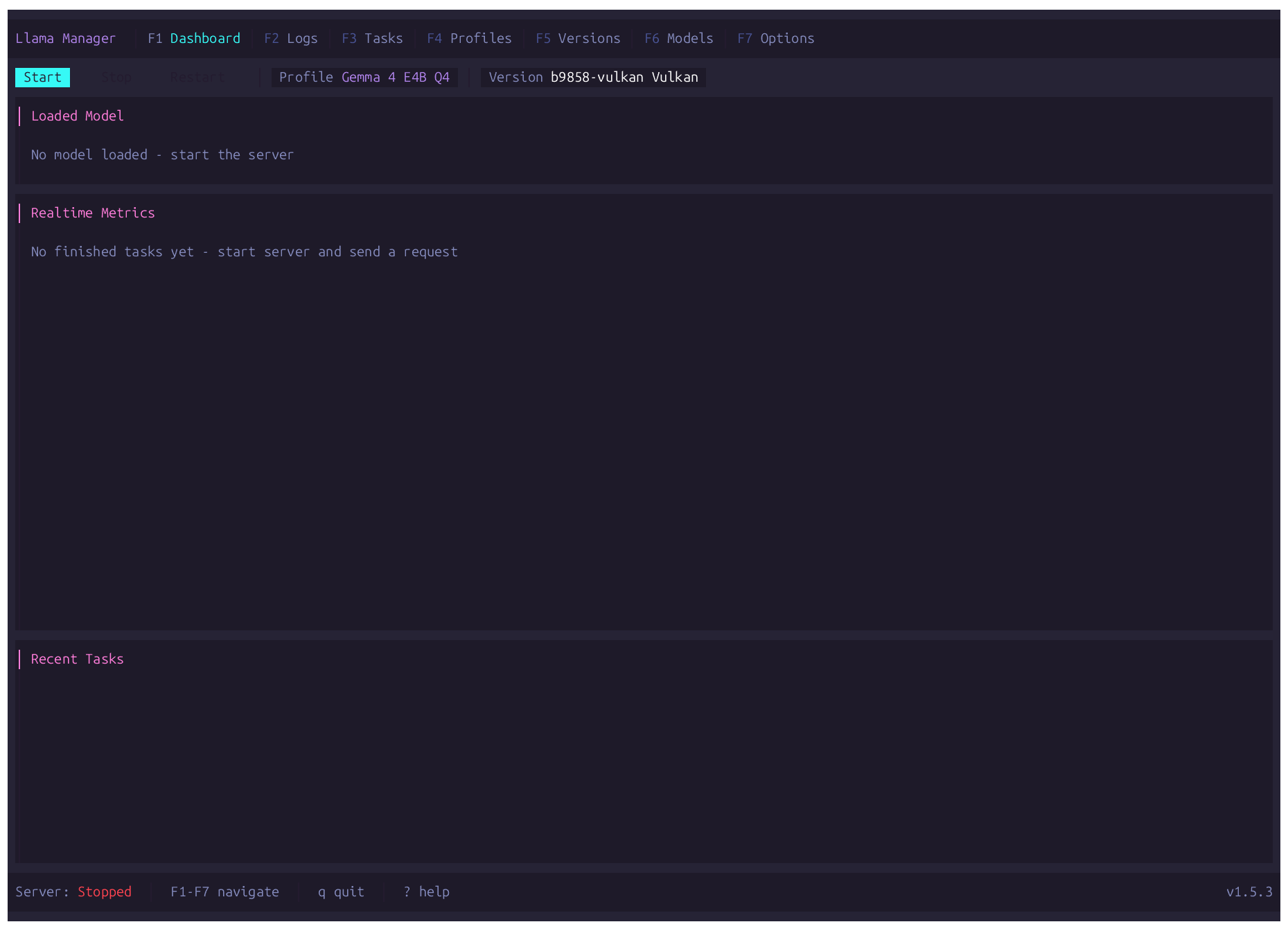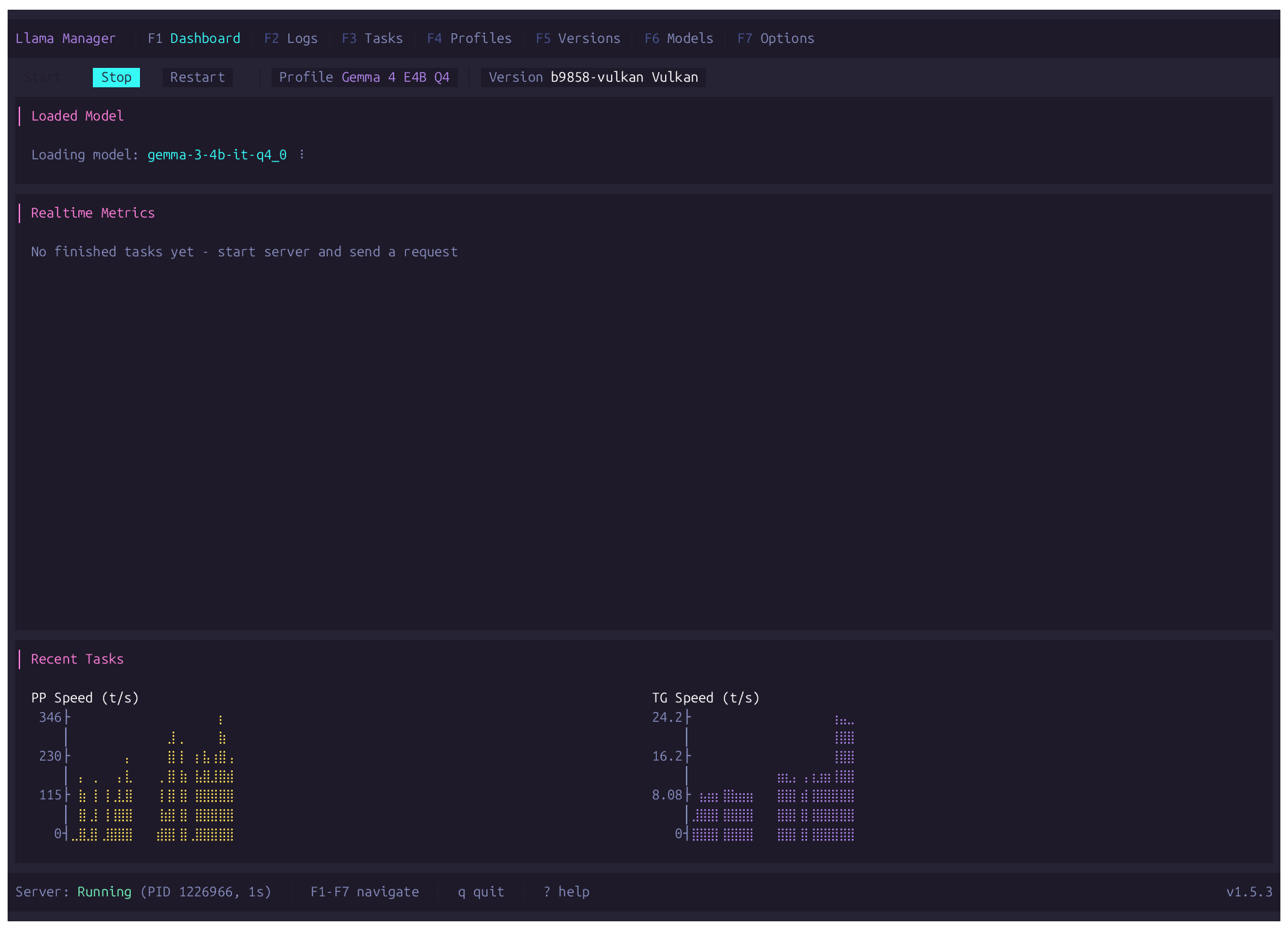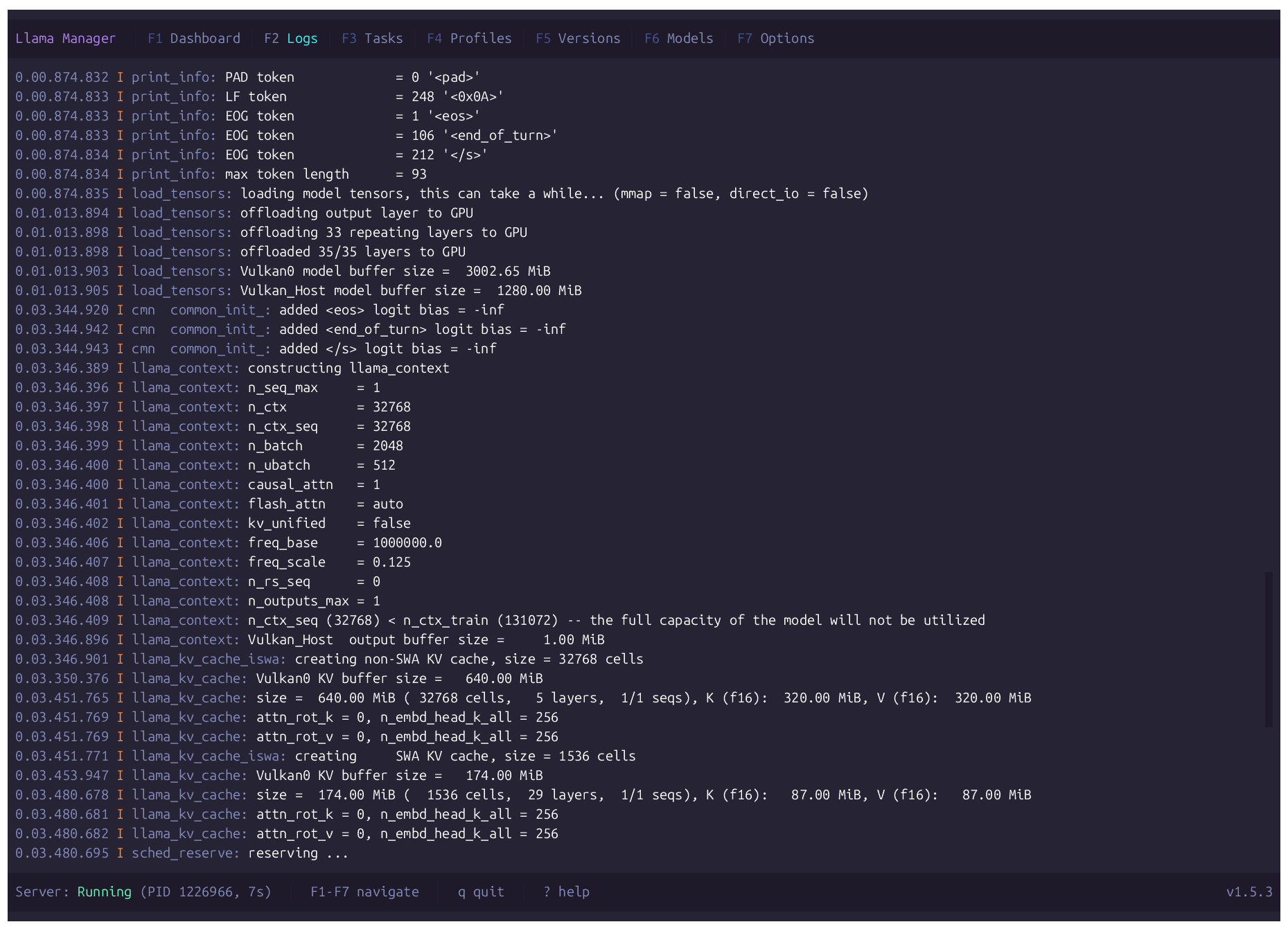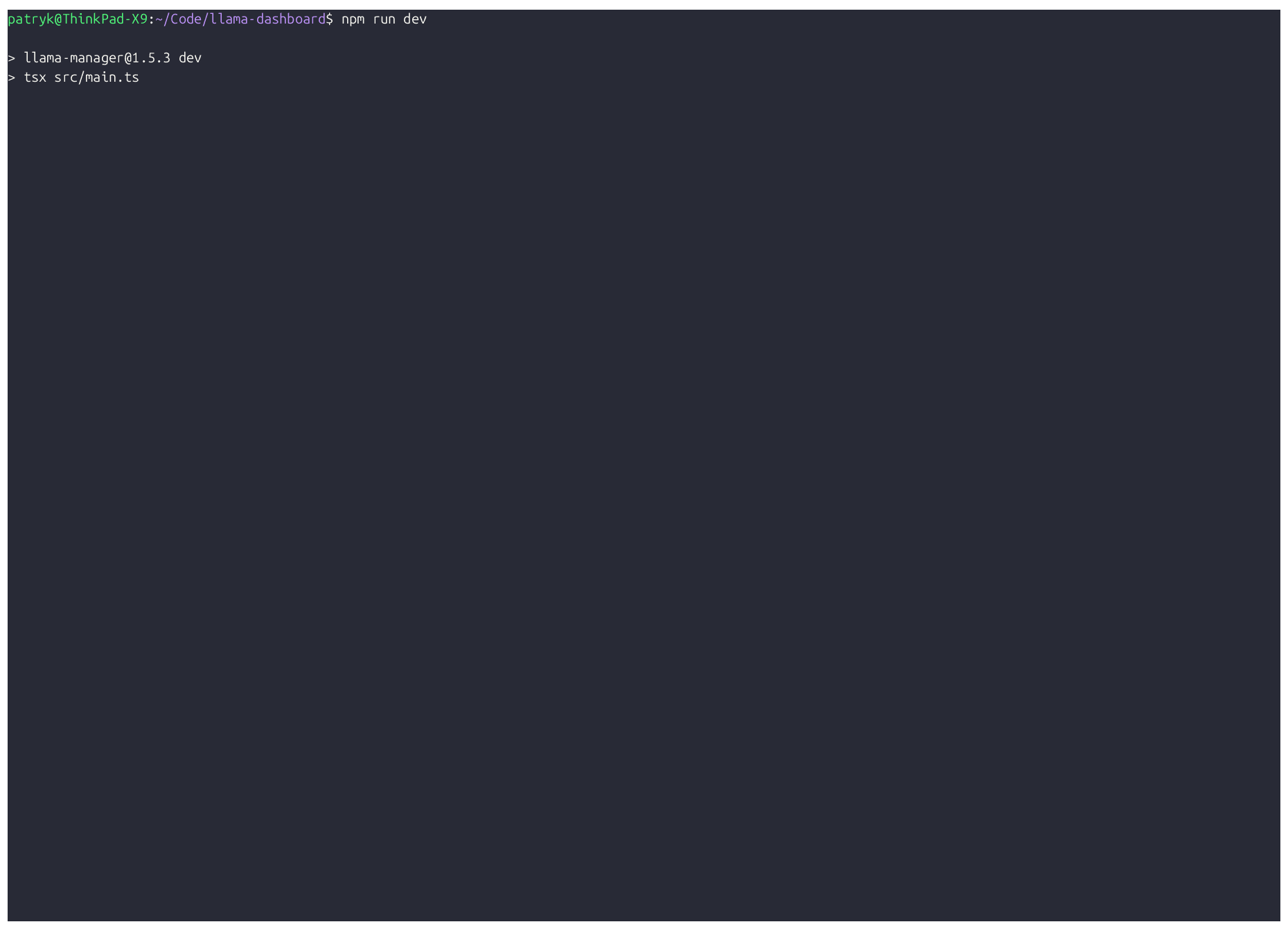
A terminal UI for managing llama.cpp — start and control the server, manage versions, download GGUF models from Hugging Face, and monitor inference performance in real time.
$
npm install -g llama-manager
 Apache 2.0
Node 18+
Apache 2.0
Node 18+